小米汽车AgentThink, 专治大模型幻觉, 推理能力超越GPT-4o
2025年5月,小米汽车联合清华大学发表论文AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving,22位作者,小米汽车员工占11位,清华大学学生占7位,首席作者Kangan Qian是在清华大学毕业后进入小米汽车实习期间完成这篇论文。
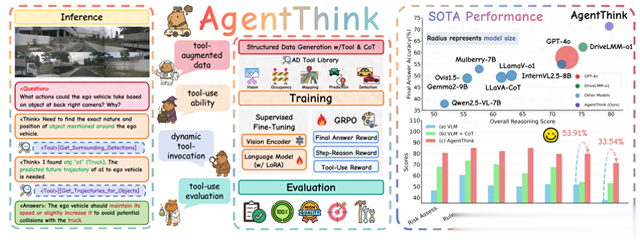
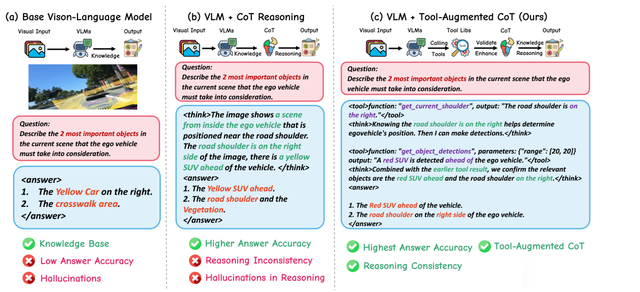
平心而论,AgentThink并无多少创新,其核心理念利用类人记忆工具库避免VLM出现幻觉,让VLM能够清晰界定能力边界。基本复制了2023年11月南加州大学、斯坦福大学和英伟达联合的论文《A Language Agent for Autonomous Driving》提出的AgentDriver理念,不过对于要考虑量产的车企来说,创新不是关键,可靠才是关键。
比如一辆汽车在宁静的郊区街道上行驶的场景。突然,一个气球从路上飘过,尽管气球是无害障碍物,且很快消失了,但人类驾驶员利用丰富的经验知识,不仅感知到气球的即时存在,还能推理出很有可能有小孩子要过道路追逐气球,会立刻减速。与人类驾驶员不同,缺乏这种推理和经验预期的自动驾驶车辆可能会在传感器检测到孩子之前继续驾驶,这只能留出更窄的安全空间。驾驶系统中人类先验知识的重要性变得非常明显:驾驶不仅仅是关于对可见事物的反应,还包括在系统需要推理和应对其不存在的情况下,考虑和应对可能的情景。尽管其有效,但这个“感知-预测-规划”框架过于简化了人类驾驶过程,并无法完全模拟驾驶场景的复杂性。
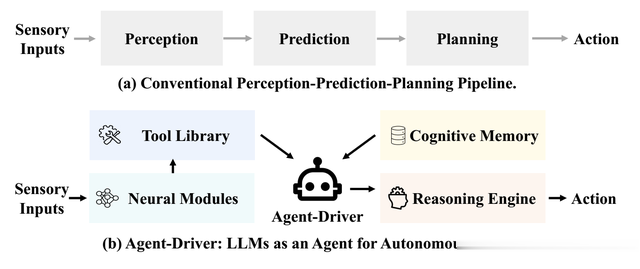
将人类先验知识集成到自动驾驶中的主要障碍在于人类知识和基于神经网络的驾驶系统之间的不兼容性。人类知识可以自然地存储和作为语言表示利用,他们的推理过程也可以通过语言进行解释。然而,传统的驾驶系统依赖于设计用于处理数值数据输入的深度神经网络,如感知信号、边界框和轨迹等。但LLM语言大模型的出现让这成为可能,将自然语言作为统一的接口,无缝地将基于语言的人类知识和推理能力集成到神经网络系统。利用LLMs作为系统组件之间的交互调度器,从根本上改变了传统的感知-预测-规划框架。
AgentDriver整体框架
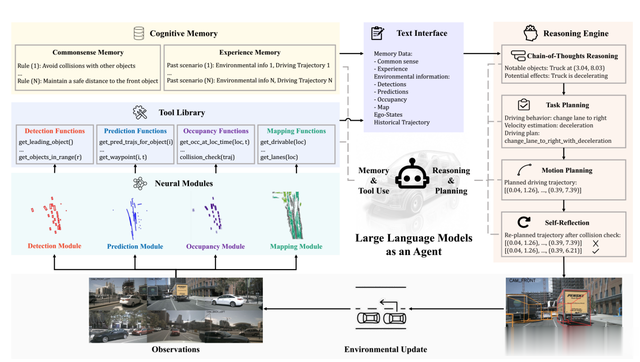
利用文本作为统一的接口,并基于神经模块提出一个工具库,用于动态收集基于文本的环境信息。工具库的四个神经模块是检测、预测、占用和地图模块,它们分别处理来自观测的传感器数据,并生成检测边界框、未来轨迹、占用网格和地图。小米的AgentThink几乎全部照搬,只是多了一个视觉信息visual info。
通过工具库中的函数,LLM可以通过动态函数调用来学习收集必要的环境信息。具体来说,LLM首先提供一些初始信息,如当前状态或视觉输入,以便进行后续决策。然后,LLM会被询问是否需要激活特定的神经模块,即检测、预测、占用和地图。如果LLM决定激活一个神经模块,与该模块相关的函数将被提供给LLM,LLM可以选择调用一个或多个这些函数来收集所需的信息。通过多次对话,LLM最终收集了当前环境的所有必要信息。利用LLM的推理能力来确定对决策过程真正重要的环境信息,从而减少了当前系统中的冗余。此外,只有在LLM决定调用相关函数时,神经模块才会被激活,这为系统带来了灵活性。
人类驾驶员使用常识进行导航,例如遵守当地交通规则,并在类似情况下利用驾驶经验。然而,将这种能力适应到传统的感知-预测-规划框架中并非易事。通过与认知记忆的交互,作者的方法解决了这个问题。具体来说,认知记忆存储了基于文本的常识和驾驶经验。
基于LLM的模糊搜索
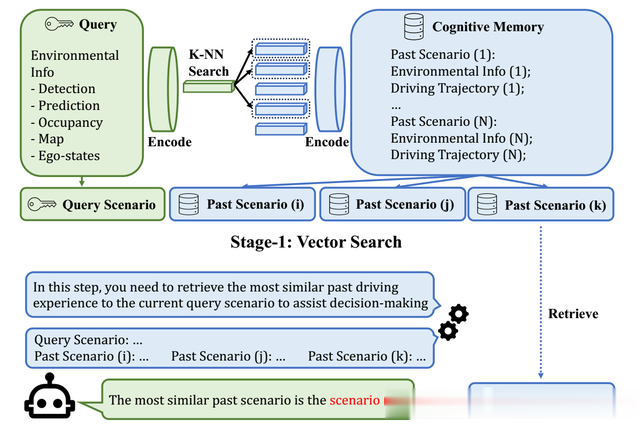
对于每个驾驶场景,利用函数调用收集的环境信息作为查询,在认知记忆中搜索类似的过去经验来帮助决策。认知记忆包含两个子记忆:常识记忆和经验记忆。
常识记忆。常识记忆包含了司机通常需要在道路上安全驾驶所需的基本知识,例如交通规则和关于高风险行为的知识。有必要指出的是,常识记忆完全是基于文本的,并且完全可配置,也就是说,用户可以通过将不同类型的知识写入内存来为不同的驾驶条件自定义常识记忆。
经验记忆。经验记忆包含了一系列过去的驾驶场景,每个场景都由当时的环境信息和随后的驾驶决策组成。通过检索最相似的经验并参考他们的驾驶决策,系统增强了做出更知情和有弹性的驾驶决策的能力。
AgentDriver提出了一种创新的两阶段搜索算法,有效地在经验记忆中搜索最相似的过去驾驶场景。第一阶段受到了向量数据库的启发,输入查询和记忆中的每个记录为嵌入,并通过在嵌入空间中进行K近邻搜索来检索前K相似的记录。由于驾驶场景相当多样化,基于嵌入的搜索受到所采用编码方法的限制,导致其泛化能力不足。为了克服这个挑战,第二阶段引入了LLM基础的模糊搜索。然后,LLM被要求根据查询对这些记录进行排名。这个排名基于LLM的隐式相似性评估,利用其在概括和推理方面的能力。
AgentDriver全流程
小米的AgentThink对于认知记忆并未提及,可能和工具库在一起。
AgentThink整体框架
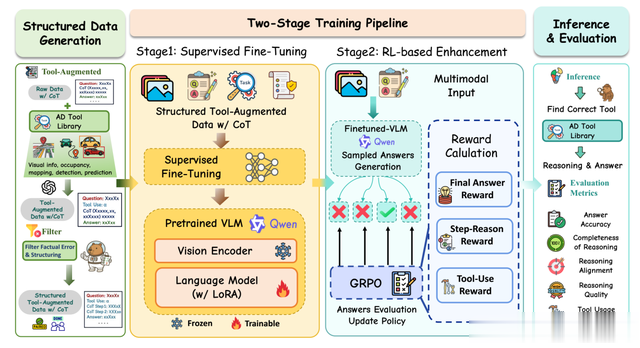
AgentThink在工具库上通过基础单视图视觉工具(例如开放词汇目标检测器和深度估计器)对其进行增强。这些技术共同实现针对各种感知和预测任务的全面环境信息提取。初始的工具集成推理步骤和答案由 GPT-4o 自动生成,并由提示模板引导。该模板旨在引出指令 L 的工具增强推理链,而非直接答案。
每个推理步骤 R_t 包含五个关键要素:所选工具 (Tool_i)、生成的子问题 (Sub_i)、不确定性标志 (U F_i)、猜测答案 (A_i) 以及下一步行动选择 (AC_i),例如继续推理还是得出结论。如果内部知识足以满足 Sub_i 的要求,则输出 A_i 且 U F_i = False;否则,U F_i = True 且 A_i 留空。重复此过程,为每个问答对采样 N 个结构化推理轨迹。单独的 LLM 审核每个数据的事实准确性和逻辑一致性,并修剪步骤不匹配或结论不受支持的样本。最终生成一个高质量的语料库,将明确的工具使用与连贯、可验证的推理相结合。
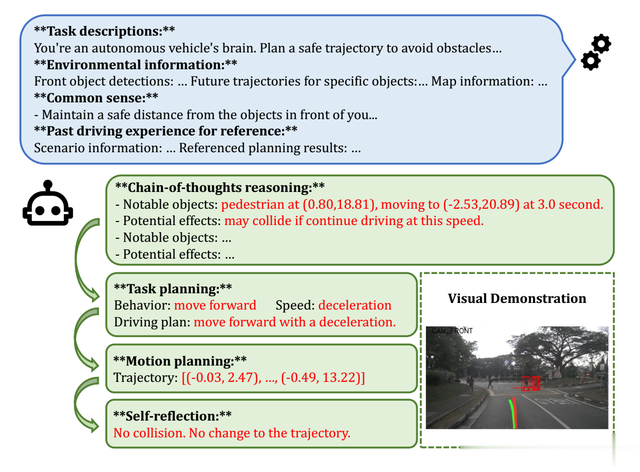
AgentThink的思维链
AgentThink强调了工具库增强思维链。
AgentThink的创新点就是增加了两级微调,这也是目前VLM的固定流程,基本上都是如此,一级是监督微调对工具增强型 CoT 数据集执行 SFT,以预热模型生成推理链和适当工具调用的能力。每个训练样本表示为 τ = (V, L, T_R, A),其中 V 表示视觉输入,L 表示语言指令,T_R 表示逐步推理,A 表示最终答案。训练目标是最大化生成 T_R 和 A 的可能性。第二阶段就是基于GPRO的强化学习RLHF,为了引导模型实现准确、可解释且工具感知的推理,设计一个包含三个主要部分的结构化奖励函数:最终答案奖励、分步推理奖励和工具使用奖励。
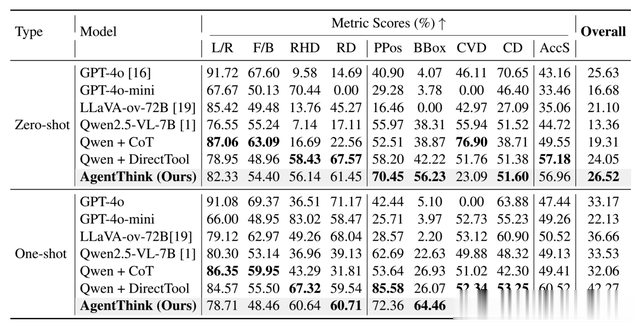
AgentThink的空间理解能力打分,使用了武汉大学与中科慧拓提出的DriveMLLM benchmark,L/R代表左右边界,F/B代表前后边界,Relative Horizontal Distance关联水平距离 (RHD), Relative Distance关联距离 (RD), Camera Vertical Distance摄像头垂直距离 (CVD), Camera Distance 摄像头距离(CD),Position Localization Accuracy 定位精度(Task PPos) ,Bounding Box Accuracy 边界框精度(Task BBox) ,The Aggregate Accuracy Score累积精度 (AccS)。
AgentThink用 Qwen2.5-VL-7B 作为基础模型,并冻结视觉编码器。通过 LoRA 应用 SFT,然后进行 GRPO 微调。将每台设备的训练批次大小设置为 1。所有实验均使用 16 块 NVIDIA A800 GPU 进行。在 GRPO 微调阶段,对每个问题进行 2 次展开。零样本情况下,AgentThink相比GPT-4o的优势并不明显,毕竟GPT-4o参数量大约2000亿,GPT4o-mini的参数量是80亿,相比GPT4o-mini优势明显,单样本下,即使面对2000亿参数的GPT-4o也是优势明显。
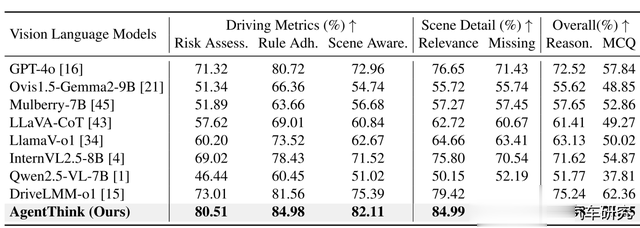
在武汉大学与中科慧拓提出的DriveMLLM benchmark,Risk Assessment风险评估是对目标风险大小进行评估,能够分辨出高风险目标如行人或小孩。Traffic Rule Adherence是交通规则遵守程度,Scene Awareness and Object Understanding场景认知和目标理解能力,也明显在GPT-4o之上。
AgentDriver的开环成绩
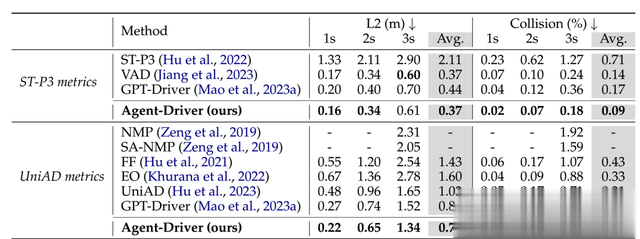
这个成绩放在2023年11月可算第一,但放到今天就不太理想了,不过LLM并不适合输出精确的waypoints坐标信息,因此小米和清华大学只是做了VLM,而不是VLA,A还是由扩散模型来做更合适。此外,工具库显然是个动态工具库,这个工具库显然是传统感知算法那一套,也就是说这是个双系统,一套VLM负责解析交通空间、交通规则、分析风险,一套传统算法系统做工具库增强VLM。
端到端自动驾驶已经基本定型,各大厂家目前的焦点一是路径规划领域的扩散模型,二是世界模型生成长尾数据,三就是用传统算法工具库增强VLM,消除VLM幻觉。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。